ChatGLM-6B 部署
安装 CUDA 和 cuDNN
CUDA(Compute Unified Device Architecture)是由 NVIDIA 开发的一种并行计算平台和编程模型。它允许开发者使用 NVIDIA 的 GPU(图形处理器)进行通用目的的并行计算,包括深度学习、科学计算、图像处理等。CUDA 提供了一套编程接口和工具,使开发者能够使用标准的 C/C++ 编程语言来利用 GPU 的并行计算能力。通过 CUDA,开发者可以编写 CUDA C/C++ 代码,并将其与传统的 CPU 代码结合,实现在 CPU 和 GPU 之间的协同计算。
直接安装 CUDA Toolkit
cuDNN(CUDA Deep Neural Network)是由 NVIDIA 开发的一个针对深度神经网络的加速库。它是建立在CUDA平台之上的,旨在提供高性能的深度学习计算功能。cuDNN 针对深度神经网络的常见操作进行了优化,包括卷积、池化、规范化和激活函数等。它提供了高度优化的 GPU 实现,利用 GPU 的并行计算能力和高带宽存储,加速深度学习模型的训练和推理过程。
它默认安装到:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1
直接安装 NVIDIA cuDNN,这个需要注册后填个表就行了,下载好后将 bin、include、lib 文件夹里的文件复制到 CUDA 安装路径同名文件夹即可。
如果遇到 AssertionError Torch not compiled with CUDA enabled 问题
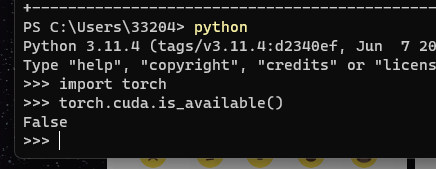
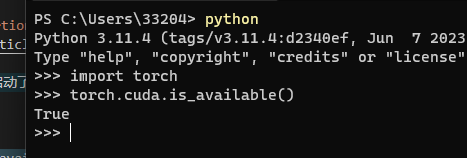
先检查当前是否启动了 Cuda
import torch
torch.cuda.is_available()
# 检查是否是安装的 GPU 版本
print(torch.__version__)
如果是 CPU 版本的就是下载错误了
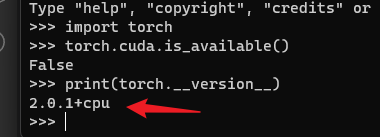
先卸载相应的框架
pip uninstall torch
pip uninstall torchvision
检查当前安装的 Cuda 版本
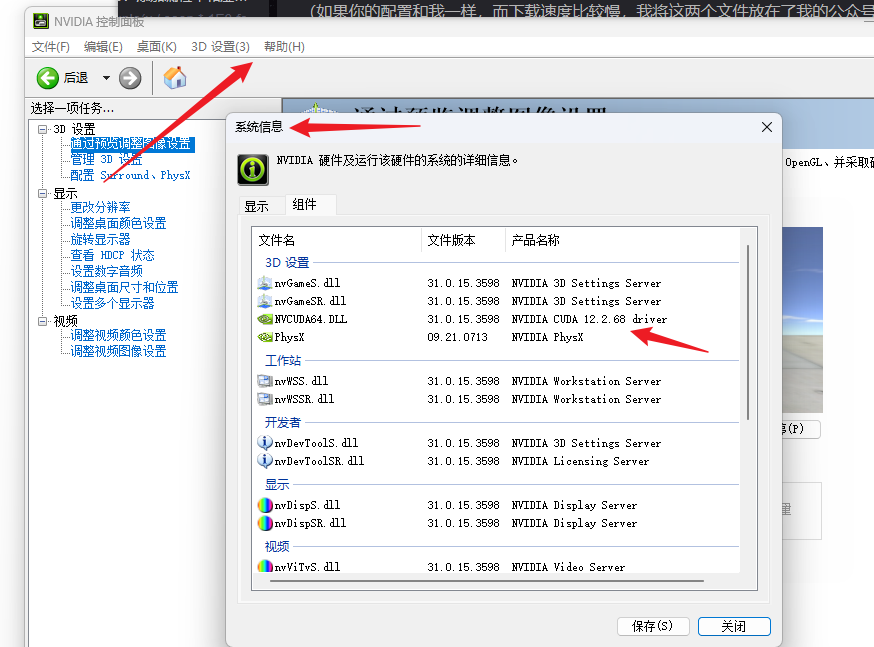
然后到官网找到最新版的
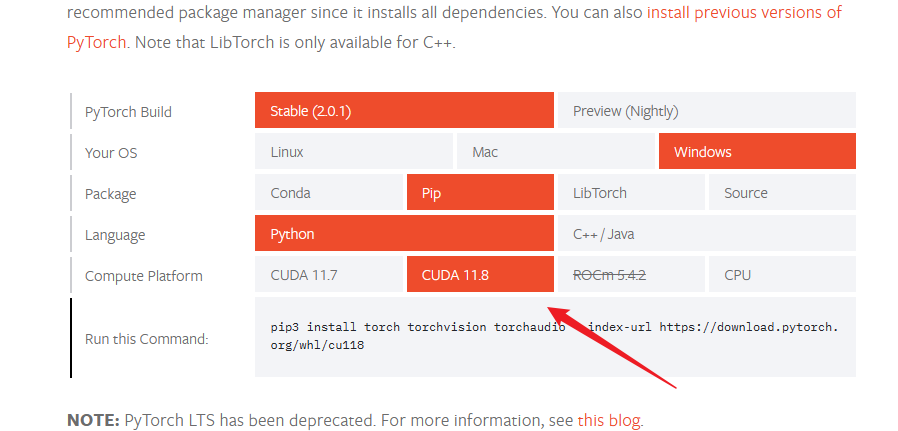
这里虽然没有 12 的版本,但是下载 118 的也是可以的
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118

使用 pip list 查看安装的版本是否正确
再次检查是否启动了 Cuda
如果项目本身已经使用了虚拟环境,那直接把这个环境删了,重新创建一个就行了
搭建环境
git clone git@github.com:THUDM/ChatGLM-6B.git
pip install -r requirements.txt
下载 int4 量化的模型,直接全部下载下来丢里面
然后运行 python web_demo.py 就可以了
微调模型
微调模型(Fine-tuning)是指在一个已经预训练好的模型基础上,通过在新的任务或数据集上进行进一步的训练,以使模型适应新任务或数据集。
通常,预训练模型是在大规模的数据集上进行训练,例如 ImageNet 数据集上的图像分类任务。这使得预训练模型具有了对通用特征的学习能力。然后,将预训练模型用于新的任务时,可以通过微调来使模型更好地适应新任务的特定特征和数据分布。
微调的过程通常包括以下几个步骤:
- 冻结部分层:通常,预训练模型的底层(靠近输入层)学到了通用的特征,而高层(靠近输出层)学到了更具任务特定性的特征。在微调过程中,通常会冻结预训练模型的底层,即保持其参数不变,而只更新高层的参数。
- 替换输出层:预训练模型的输出层通常是与原任务相对应的分类层,而在微调时,需要将其替换为适合新任务的输出层。这可以根据新任务的要求来设计,并且输出层的参数将从头开始训练。
- 训练新数据:将新的数据集输入微调后的模型,通过反向传播和梯度下降等方法来更新模型参数。在微调过程中,通常使用较小的学习率,以避免过大的参数更新,从而更好地保留预训练模型的知识。
通过微调,模型可以在较少的训练步骤中从预训练的初始状态快速适应新任务或数据集。微调利用了预训练模型在大规模数据集上学到的通用特征,从而可以在相对较少的标注数据下实现较好的性能。
需要注意的是,微调的效果取决于预训练模型的质量和相似性任务之间的差异。如果预训练模型和新任务之间的差异较大,可能需要更多的微调和调整来适应新任务的特点。
模型量化是什么?
模型量化(Model quantization)是一种用于减少神经网络模型大小和计算量的技术。在深度学习中,神经网络模型通常由大量的参数组成,这些参数需要大量的内存和计算资源来存储和执行。这对于在资源受限的设备上部署模型(如移动设备或嵌入式系统)可能是一个问题。
模型量化通过减少模型中参数的表示精度来解决这个问题。常见的量化方法是将浮点数参数转换为更低精度的表示,如8位整数或4位整数。这样做可以大大减少模型的内存占用和计算需求,使得模型可以更高效地在资源受限的设备上运行。
模型量化的过程通常包括以下几个步骤:
- 参数量化:将浮点参数转换为固定位数的整数表示。
- 量化训练:在量化的表示下对模型进行训练,通常会调整模型的权重和激活函数等。
- 量化推理:将量化的模型部署到目标设备上进行推理,使用固定位数的整数表示进行计算。
需要注意的是,模型量化会引入一定的精度损失,因为量化后的参数无法完全表示原始浮点数的精确值。这可能会导致模型性能的下降,但通常可以通过微调和优化来减轻这种影响。
说白了就是量化后的版本生成的效果不如完整的版本好